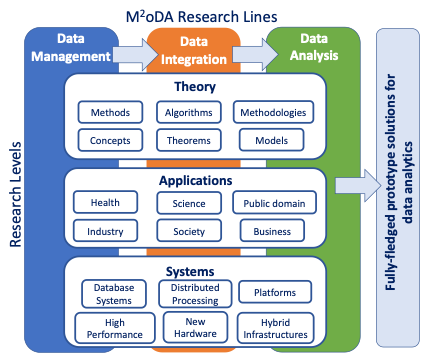
The management, processing and analysis of massive data is one of the most important drivers for societal growth, efficiency and sustainability. To cope with this trend, we need to invest in research of novel data technologies, capable of supporting the collection, management, transfer and analytical exploitation of large data, addressing holistically emerging problems in diverse sectors (e.g., healthcare, industry, science etc.) and areas of public interest (e.g., transportation, aviation, etc.). M2oDA is a new research group and lab that develops research along the lines of data management, integration, and analysis on three levels, namely: theory, applications and systems, towards the creation of fully-fledged prototype computing solutions that perform data analytics. The utmost goal of M2oDA is to produce ensembles of techniques that realize our vision of a novel computing paradigm, that of ubiquitous analytics.
1. Data management on large-scale infrastructures
Modern data management in the edge-cloud continuum
M2oDA creates prototype data management techniques that serve infrastructures spanning edge network devices, intermediate fog network deployments and cloud computing. Directions for technology development are monitoring and prediction modules, pre-processing and caching services, customizable optimization modules etc. Our intention is to empower classical and novel algorithms by exploiting the hardware capabilities. We employ Big Data platforms, such as Apache Spark, Flink, Kafka etc., and investigate their potential to build innovative systems. We serve real modern Big Data applications, which are computationally- and/or data-intensive. Such applications may span geographic regions, heterogeneous and distributed infrastructures and have thousands of users that assume multifarious roles. A prominent example are Internet-of-Things (IoT) applications. Potentially, this research line will also focus on the provision of serverless solutions for such applications.
Multi-objective optimization and data economics
Current data management allows for one-dimensional optimization, usually time or a type of cost. M2oDA develops optimization techniques that cover data management requirements in traditional, recent and modern computing environments and address dimensions corresponding to data, workload and computing resources. We focus on identifying ways to construct optimal objectives pertaining to performance, quality, cost and reliability. In this effort we include the creation of frameworks for data economics. Data is at the core of modern businesses. However, it comes with special characteristics, such as non-depletion with use, variable or increasing value depending on use, expensive to protect from theft or misuse etc. Our utmost goal is to employ the proposed frameworks for the creation of data policies within business models, and data market paradigms.
Ubiquitous information sharing
The emerging world of ubiquitous computing encounters the challenge of efficient management of large dynamic disseminated data collections. Most such data do not even reside in databases, but in web pages, social networking sites, blogs, personal data on mobile devices, etc. Beyond efficiently and reliably storing this data, it is vital to extract knowledge tailored to the user specifics that is transparent to the user herself, by enabling querying, analysis and transformation. M2oDA creates techniques for dynamic, adaptable, but also approximate and evolvable mappings of data sources, which enable on-the-fly and flexible information sharing, while data collections and/or computing environments may change. Furthermore, M2oDA proposes techniques for adaptable accessing and processing of the data, depending on user specifics, as well as on the characteristics of the computing environment.
2. Modern data integration
Data virtualization and on-demand data integration
Modern analytics aim at diverse datasets produced by a variety of applications or collected by autonomous agents and stored in dispersed locations. Such data are stored in relational or no forms, in a persistent (flat files, spreadsheets) or transient manner (streams) and are inherently heterogeneous semantically and structurally. The heterogeneity extends from data to analysis itself, since users of analytics environment (data scientists, data engineers, simple end-users, data regulation officers etc) want to deploy different analysis projects, related to traditional BI, data exploration, data mining, prediction etc. Multiple systems and platforms need to coexist, integrated and federated. M2oDA develops techniques and tools that realize the paradigm of data virtualization, enabling flexible and agile data sharing and trade for multiple user types. We create late-bound schemas by developing novel data models that can be built agilely, on-demand and in a bottom-up fashion.
Data privacy and reliability
The opportunities created by Big Data analytics need to be weighted with the privacy and reliability risks. M2oDA proposes techniques that coordinate data replication and movement within private and public computing environments, so that they enable the declarative expression and adaptable enforcement of data. Depiction of M2oDA research privacy and reliability requirements, according to profiles of users, data sources and type of infrastructures. One of our primary goals, is to accommodate in data management transparent adherence to data regulations. Such a need is prevalent, especially in environments that perform analytics in a collaborative manner, and/or on data collections that come from various data sources, which may also need to adhere to governmental rules, and federal and provincial law.
Approximate querying and guarantees of approximation
Querying Big Data in an approximate manner has gained attention. M2oDA focuses on the relaxation of expressions, the alleviation or postponement of execution or partial execution, for computation-intensive analytics queries on big data graphs. Our interest lies in the development of methods that measure and take into account query similarity, resource utilization, and give guarantees for performance and cost. Furthermore, we explore the employment of models, produced by machine and deep learning techniques, in the approximation of both the expression of analytical queries, as well as the query answers on Big Data collections.
3. Data analysis
Real-time analysis and forecasting
There is a growing demand for real-time analysis from organizations in industry and research, related to biology, society and environment etc. M2oDA develops techniques for the analysis of time-series data with the ultimate goal of forecasting. The techniques aim to compare the accuracy of various models in order to test their suitability on a given dataset. We use forecasting methods which handle multivariate time-series and compare them with models trained on univariate time-series, which might still achieve higher accuracy for specific cases of datasets. Moreover, using raw data for prediction can affect negatively forecast accuracy. Hence, we also aim at data pre-processing, as it ensures the quality of the dataset, so that forecasting is not affected by non-causal effects.
Analysis of big data graphs
Analysis depends on the discovery of data connections, which are suitably modeled in graph format in many use cases, such as contact tracing, cybersecurity, drug interaction, social networks, recommendation engines, supply chains, and they may represent interactions or relations of people, objects, organizations, processes, events, molecules, substances. The analysis of Big Data graphs depends on algorithms designed to run on graph database systems. M2oDA develops algorithms capable of distributed deployment and integrated with novel data storage. We work on community detection producing scalable algorithms that use traditional and/or new hardware. We capitalize on hyperbolic embedding of large graphs to optimally employ ML/DL. Understanding the analysis results can be greatly assisted with effective visualization. M2oDA also develops tailored visualization techniques enabling a wide audience to access and explore vast datasets with complex relationships. The goal is to offer efficient rendering of real-time analysis and the conduction of visual querying, tasks that remain elusive until today.
Transfer learning
Transfer learning has gained significant interest rooted in its promise to tackle the most important limitation of ML techniques, which is that train and test data have to be drawn from the same domain, and even small discrepancies may lead to great prediction degradation. M2oDA aims to leverage methodologies for transfer learning in order to create relevant techniques for different applications within and across domains. These include the definition of semantic and structural properties of data collections, organized in ontologies and taxonomies. Employing the latter we explore ways for transferring learned models, choosing between homogeneous and heterogeneous transfer learning.